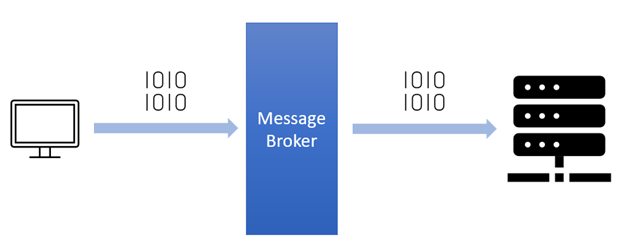
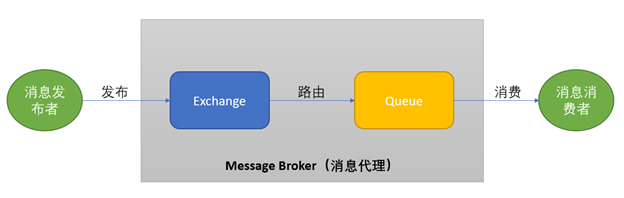
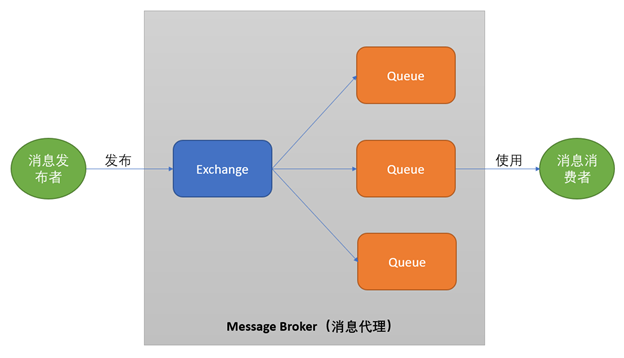
如果加大队列后仍然有非常偶发的队列溢出的话,可以暂且容忍。如果仍然有较长时间处理不过来怎么办?另外一个做法就是直接报错,不要让客户端超时等待。例如将Redis、Mysql等后端接口的内核参数tcp_abort_on_overflow为1。如果队列满了,直接发reset给client。告诉后端进程/线程不要痴情地傻等。这时候client会收到错误“connection reset by peer”。牺牲一个用户的访问请求,要比把整个站都搞崩了还是要强的。
funcHandler(w http.ResponseWriter, r *http.Request) { m := r.Method if m == http.MethodPut { put(w, r) return } if m == http.MethodGet { get(w, r) return } // 与上一版本多一个DELETE方法处理del函数 if m == http.MethodDelete { del(w, r) return } w.WriteHeader(http.StatusMethodNotAllowed) }
objects.del函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
funcdel(w http.ResponseWriter, r *http.Request) { name := strings.Split(r.URL.EscapedPath(), "/")[2] // 以name为参数调用es.SearchLaestVersion,搜索该对象最新的版本 version, e := es.SearchLatestVersion(name) if e != nil { log.Println(e) w.WriteHeader(http.StatusInternalServerError) return } // 插入新的元数据,接受元数据的name, version, size和hash // hash 为空字符串表示这个一个删除标记 e = es.PutMetadata(name, version.Version+1, 0, "") if e != nil { log.Println(e) w.WriteHeader(http.StatusInternalServerError) return } }
funcput(w http.ResponseWriter, r *http.Request) { // 先从HTTP请求头部获取对象的散列值 hash := utils.GetHashFromHeader(r.Header) if hash == "" { log.Println("missing object hash in digest header") w.WriteHeader(http.StatusBadRequest) return }
// 以散列值作为参数调用stroreObject c, e := storeObject(r.Body, url.PathEscape(hash)) if e != nil { log.Println(e) w.WriteHeader(c) return } if c != http.StatusOK { w.WriteHeader(c) return }
// 从URL中获取对象的名字和对象的大小 name := strings.Split(r.URL.EscapedPath(), "/")[2] size := utils.GetSizeFromHeader(r.Header) // 以对象的名字、散列值和大小为参数调用es.AddVersions给对象添加新版本 e = es.AddVersion(name, hash, size) if e != nil { log.Println(e) w.WriteHeader(http.StatusInternalServerError) } }
客户端通过GET方法发起对象定位请求,接口服务节点收到该请求后通过dataServers exchange会向数据服务层群发一个定位消息,然后等待数据服务节点的反馈。如果有数据服务节点发回确认消息,则返回该数据服务节点的地址;如果超过一定时间没有任何反馈,则返回HTTP错误代码404 NOT FOUND.
客户端向接口服务发送HTTP的PUT 请求并提供了<object_name>和<contentof object>,接口服务选出一个随机数据服务节点并向它转发这个PUT请求,数据服务节点将<content of object>写入$STORAGE_ROOT/objects/<object_name>文件。
接口和存储分离的对象GET流程
客户端的GET 请求提供了<object_name>,接口服务在收到GET请求后会对该object进行定位,如果定位失败则返回404 Not Found;如果定位成功,接口服务会接收到某个数据服务的地址,就可以向该地址转发来自客户端的GET请求,由数据服务读取本地磁盘上的文件并将其内容写入HTTP响应的正文。
具体实现
数据服务
为支持新的功能,数据服务的在实现上扩展了单机版的相关功能:
1 2 3 4 5 6
funcmain() { go heartbeat.StartHeartbeat() go locate.StartLocate() http.HandleFunc("/objects/", objects.Handler) log.Fatal(http.ListenAndServe(os.Getenv("LISTEN_ADDRESS"), nil)) }
# start test env export RABBITMQ_SERVER=amqp://test:test@localhost:5672 export ES_SERVER=localhost:9200
LISTEN_ADDRESS=10.29.1.1:12346 STORAGE_ROOT=/tmp/1 go run ../dataServer/dataServer.go & LISTEN_ADDRESS=10.29.1.2:12346 STORAGE_ROOT=/tmp/2 go run ../dataServer/dataServer.go & LISTEN_ADDRESS=10.29.1.3:12346 STORAGE_ROOT=/tmp/3 go run ../dataServer/dataServer.go & LISTEN_ADDRESS=10.29.1.4:12346 STORAGE_ROOT=/tmp/4 go run ../dataServer/dataServer.go & LISTEN_ADDRESS=10.29.1.5:12346 STORAGE_ROOT=/tmp/5 go run ../dataServer/dataServer.go & LISTEN_ADDRESS=10.29.1.6:12346 STORAGE_ROOT=/tmp/6 go run ../dataServer/dataServer.go &
LISTEN_ADDRESS=10.29.2.1:12346 go run ../apiServer/apiServer.go & LISTEN_ADDRESS=10.29.2.2:12346 go run ../apiServer/apiServer.go &
使用curl测试:
1 2 3 4 5 6 7 8
#!/bin/bash
curl -v 10.29.2.1:12346/objects/test2 -XPUT -d"this is object test2"
SAN: Storage Area Network 的简称。和NAS的区别是SAN只提供了块存储,而把文件系统的抽象交给客户端来管理。SAN 的客户端和服务端之间的协议有FibreChannel、iSCSI、ATA over Ethernet(AoE)和 HyperSCSI。对于客户端来说,SAN就是一块磁盘,可以对其格式化、创建文件系统并挂载。
在对象存储中,通常使用PUT方法来上传一个对象。客户端的PUT请求提供了对象的名字<object_name>和对象的数据<content of object>,它们最终被保存在本地磁盘上的文件STORAGE_ROOT/objects/<object_name>中。$STORAGE_ROOT环境变量保存着在本地磁盘上的存储根目录的名字。
对象GET
1 2
GET /objects/<object_name> 响应正文 (Response Body)
客户端通过GET方法从服务器上下载一个对象,服务器在本地磁盘上查找并读取该对象,如果该对象不存在,则服务器返回HTTP错误代码404 Not Found。
// 检查HTTP请求方法:PUT则调用put函数,GET则调用共get函数。其余则返回405 Method Not Allowed错误代码 funcHandler(w http.ResponseWriter, r *http.Request) { m := r.Method //Method记录该HTTP请求的方法 if m == http.MethodPut { put(w, r) return } if m == http.MethodGet { get(w, r) return } //写HTTP响应的代码 w.WriteHeader(http.StatusMethodNotAllowed) }
All transfer of value on the go channels happens with the copy of value. channel 的发送和接收操作本质上都是 “值的拷贝”,无论是从 sender goroutine 的栈到 chan buf,还是从 chan buf 到 receiver goroutine,或者是直接从 sender goroutine 到 receiver goroutine。
main 程序里,先把 g 发送到 c,根据 copy value 的本质,进入到 chan buf 里的就是 0x56420,它是指针 g 的值(不是它指向的内容),所以打印从 channel 接收到的元素时,它就是 &{Ankur 25}。因此,这里并不是将指针 g “发送” 到了 channel 里,只是拷贝它的值而已。
mysql> show variables like 'transaction_isolation'; 或 select @@tx_isolation; mysql> set global transaction_isolation=0; -- 读未提交 mysql> set global transaction_isolation=1; -- 读提交 mysql> set global transaction_isolation=2; -- 可重复读 mysql> set global transaction_isolation=3; -- 串行化 set [glogal|session] transactionisolationlevel 隔离级别名称;
对于一个需要频繁使用事务的业务,第二种方式每个事务在开始时都不需要主动执行一次 “begin”,减少了语句的交互次数。如果也有这个顾虑,建议使用commit work and chain语法: 在autocommit为1的情况下,用begin显式启动的事务,如果执行commit则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务,这样也省去了再次执行begin语句的开销。同时带来的好处是从程序开发的角度明确地知道每个语句是否处于事务中。